
Building a CRUD with JavaScript - 2020s style
Introduction
During the mid-2010s IT boom, building a CRUD 1 app was a rite of passage. Numerous todo lists and bookstores were created to initiate a programmer’s experience with a technology stack. Facing a similar challenge, I’m building a Book gallery and reporting my findings here. As it’s mid-2020s, expect some prompts side by side with code, which is here
What new information I might bring? My viewpoint might be interesting. I’m a fullstack dev who builds in Angular and Java. Here, I’m going to show how I navigated the React and Node.js, with assorted technologies: Typescript, Auth.js, tRPC, Zod and Drizzle ORM. So consider this post alike to YouTube “Reaction” videos.
Rationale
Web development patterns: SPA vs BFF
Web development has different constraints to optimise for. One of them is SEO friendliness, another is feature richness. Some web apps - e.g. blog or webstore - must be SEO friendly. This requires you to send a concrete HTML from the server for every URL of your app. Say /books/war-and-peace - the web crawler fetches the HTML and reports what it has found there to the search engine. This is a Backend For Frontend (BFF) pattern.
On the contrary, if you’re building a more complex application in the browser, with a requirement to access your large UI state in a runtime continuously, you fetch a framework JavaScript code with your index.html and then load views dynamically. This is a Single Page Application (SPA) pattern
Having experience doing SPAs, I will show how BFF pattern feels different on the first glances.
Better life in the JavaScript world
Like it or not, the web is built with JavaScript. This language has a lot of quirky historical layers that can’t be removed for compatibility reasons, but the modern iteration (ECMA 6), coupled with a “use only the good parts” 2 linting are finally robust for building large systems. So, I wanted to check how far can you take your Eslint in your quest towards better type safety and cleaner coding style.
I suppose, a lot of senior frontend engineers quietly use JavaScript as a functional programming language, and this exercise tries to go their way. We’ll use a lot of readonly, consts and pure functions. As well, Zod helps validating API types, adding type guards defined with an appropriate DSL.
AI-assisted dev and demand for JavaScript roles
The businesses want JavaScript full-stack developers to build complex software with React and Node. Maybe it’s because having server and client build on one language is attractive business-wise. Maybe it’s because demands to Java/Angular enterprise app got more complex since 10 years ago, and doing a good full-stack development on those both is now too hard. There’s also a good support for React with LLMs - they tend to produce React code easier than less wide-spread Angular.
The task
Requirements
- Functional requirements
Server-side rendered gallery for Books, with ability to add and remove books for authorised users, and SEO-friendly URLs. Invariant - book price is always a prime number. - Non-functional requirements
Modern subset of JavaScript enforced by linting. Validation for your data between client and server. AGENTS.md to help with AI-assisted development. No vibe coding - a human owns every line.
Expected screens:
- login/logout
- book page
- the gallery (hide add/delete controls for non-administrators):
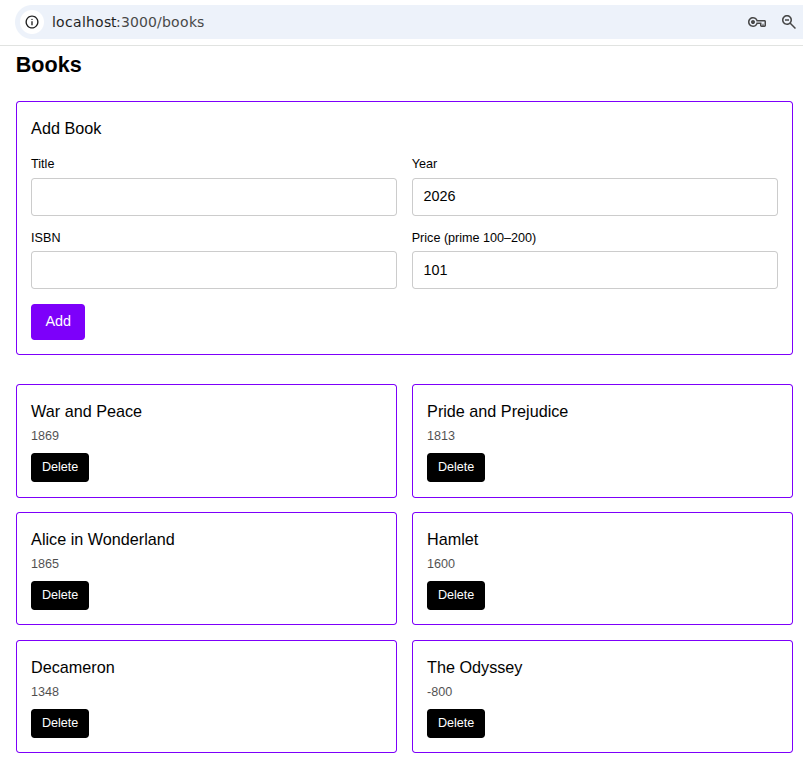
Part 1 - Scaffolding, DI and ORM
The Stack
- SSR framework - NextJS: it’s React served from a Node processs, routing by conventions, and tools to build HTTP endpoints.
- Typescript obviously for type annotations.
- Eslint to enforce coding convenions.
- SQLite as persistence, a minimal solution. Contrast with a feature-rich Postgres that would want a docker volume.
- Drizzle ORM as its grammar is closer to SQL 3.
- Zod to do runtime validation of objects.
- tRPC to build API endpoints.
- Next-Auth to provide JWT authentication with cookies.
- Tailwind - as it’s more modular than Bootstrap.
Scaffolding
After the DB is up, its tables are defined and loaded with the first schema migration, you already start to feel like it’s going live soon.
So, we’re going to have an admin password. It’s stored in .env - can’t expose secrets like that to code. So you need to hook it from .env into your seed function.
With a package called dotenv, and a basic commands like this,
drizzle-kit pushtsx src/db/seed.tsYou put everything to db:setup command for your npm run, adding also .env file with ADMIN_PASSWORD :
npm install --save-dev dotenv-cli "scripts": { //... "db:push": "drizzle-kit push", "db:seed": "tsx src/db/seed.ts", "db:setup": "npx dotenv -e .env -- npm run db:push && npx dotenv -e .env -- npm run db:seed" },Checking the database got populated: sqlite3:
pv@work:~/2026-03-01-bookstore$ sqlite3 sqlite.dbSQLite version 3.44.0 2023-11-01 11:23:50Enter ".help" for usage hints.sqlite> select * from books;1|War and Peace|1869|978-3-16-148410-0|1012|Pride and Prejudice|1813|978-3-16-148411-0|1033|Alice in Wonderland|1865|978-3-16-148412-0|1074|Hamlet|1600|978-3-16-148413-0|1095|Decameron|1348|978-3-16-148414-0|1136|The Odyssey|-800|978-3-16-148415-0|1277|Catch-22|1961|978-3-16-148416-0|1318|Buddha's Little Finger|1995|978-3-16-148417-0|1379|Sapiens|2011|978-3-16-148418-0|13910|Structure And Implementation Of Computer Programs|1985|978-3-16-148419-0|14911|Microsoft Office '97|1997|978-3-16-1484110-0|15112|Rocket Science For Dummies|2003|978-3-16-1484111-0|157sqlite>As you see, at this level there’s no difference between SPA and SSR apps. Database+ORM are presentation level agnostic, obviosly. In Spring I would’ve set up database address, admin and password; created @Entities and @Repositories. Spring as well, can create the database tables automatically. For changelogs, a Drizzle Kit is used in place of Liquibase migrations - and initially, we can go with JS->SQL to access our types.
A world on inversion of contol (IoC) and the dependency injection. Having the framework instantiate required objects (DI, an application of IoC principle) instead of hardcoding them is another best practice when building anything serious. @Bean (factory method) and @Component (auto registration of class) is the DI language in Spring, while inject() and @Injectable annotation do the same in Angular. In Next.js, this part is, frankly, missing - you import (hardcode) JS objects import { db } from "@/db";. Note that import keyword in JavaScript instantiates an object once. Every other invocation imports the cached instance, so db is a singleton as required.
npx create and your package.json:
npx create-next-app@latest . --typescript --tailwind --eslint \ --app --src-dir --no-turbopack --yes{ "dependencies": { "@trpc/client": "^11.11.0", "@trpc/next": "^11.11.0", "@trpc/react-query": "^11.11.0", "@trpc/server": "^11.11.0", "drizzle-orm": "^0.45.1", "next": "16.1.6", "next-auth": "^4.24.13", "react-hook-form": "^7.57.0", "@hookform/resolvers": "^5.2.2", "zod": "^4.3.6" }}At this level as well, there’s no difference between SPA and SSR apps. Same database and ORM. In Spring I would’ve set up database address, admin and password; created @Entities and @Repositories. Spring can be asked to create the database tables automatically. Serious projects, of course, would require changelogs because the schema would inevitably drift while already populated with data. I’m used to Liquibase migrations, and here, a Drizzle Kit should take care of the same.
Part 2 - building the API
Server
This is where the difference between SPA and BFF stack get serious. I was expecting some kind of @Controller annotation a-la ExpressJS or Spring: declare endpoints, DTOs, validation and then work with the client side to do HTTP calls with obligatory CORS setup with proxy. Reality was very different.
From the server view, Next.js is surprisingly similar to Spring Boot: as Tomcat/Jetty are application servers - they execute code to generate response - the “default server” of Next.js also executes code. There’s as well a middleware (Servlet Filter Chain in Spring and Auth.js here), and a dispatcher (Resolver with its manifest lookup) that maps creates a NextRequest. Only now the difference between stacks starts to show itself.
API and integration
No CORS because you’re calling the same URL and port. On the contrary, in Angular, for dev, you would require a proxy that gives your browser data from localhost:8080 while it believes it’s calling localhost:4200.
No need to declare shared DTOs. In Spring/Angular, this is usually done by Maven plugin “Typescript Converter” that transpiles annotate DTOs to Typescript. Here, getBooks outputs a typed array of Books for the client: bookSchema.array(), thanks to tRPC that abstracts the data transfer objects.
For endpoints, server/routers/index.ts stores a server routing config (appRouter), with tRPC’s handler at /api/trpc working as entry point:
import { fetchRequestHandler } from "@trpc/server/adapters/fetch";import { getServerSession } from "next-auth";import { appRouter } from "@/server/routers";import { authOptions } from "@/lib/auth";import { db } from "@/db";const createContext = async (opts: { readonly req: Request }) => { const session = await getServerSession(authOptions); return { db, session };};const handler = (req: Request) => fetchRequestHandler({ endpoint: "/api/trpc", req, router: appRouter, createContext: () => createContext({ req }), });export { handler as GET, handler as POST };What about the validation? We’ll discuss how the FE validates a form in part 4. On the BE, in SPA world, Java’s type system as well as linting annotations like @Null help with type validation.
As well, deserialization would throw exception if a frontend sends a wrong DTO. Here, you use zod’s Object to declare a fields and throw exception if you have extra logic on top of field types and lengths (so the business rule “Book price is a prime number between 100 and 200” is enforced here):
export const bookSchema = z.object({ id: z.number().int().positive(), title: z.string().min(1), year: z.number().int(), isbn: z.string().min(1), price: z .number() .int() .min(100) .max(200) .refine((p) => isPrime(p), "Price must be a prime number between 100 and 200"),});export const bookCreateSchema = bookSchema.omit({ id: true });After the endpoints were ready (tPRC’s query), you do npm run dev and go with curl: curl localhost:3000/books
Part 3 - Authentication
Creating and passing JWTs
Comments to JWT (JSON Web Token) based security. JWT is a base64-encoded JSON with header, claims (the authentication-carrying payload) and a signature that’s hashed using a secret key. Changing anything in JWT required updating the signature, which requires knowing a key. Nowadays they usually use RS256 algorithm to hash the claims - the private key stays on the server, the public key is available so you can read the clams, but cannot modify them. On top of that, in Next.js (BFF pattern), the JWT is also encrypted on the server - so it’s not even readable by anyone except the server 4.
So the first part is to mint a JWT. With Angular SPA’s, I was somewhat vendor-locked - I used AWS Cognito 5 to get a JWT by sending user’s credentials and an application’s client ID to the user pool. In Angular runtime, once the user is logged in, you called an AWS Amplify Auth service, and then used a HTTP Interceptor to add bearer token to your every request to the BE. This is vulnerable to XSS (cross-site scripting attack), because by default, Amplify stores the token in your Local Storage, with non-defaults harder to implement. Reasonable JWT expiration time and reducing the attack surface by granting Admin access to selected few hardened machines somewhat mitigates this.
Setting up cookie-based authentication
With this SSR stack, you don’t store JWT in LocalStorage because you don’t have to fetch it from the third party in the runtime. Instead, the server gives you cookies with nice HttpOnly attribute, preventing JS from seeing them at all, so no XSS vulnerability; plus, as said above, the JWT is also encrypted.
There’s still a problem with a CSRF, (cross-site request forgery) attacks, so we add a CSRF token to the cookies. It’s used for:
- Double-submit cookie pattern
A double-submit cookie pattern that requires attacker to provide a X-CSRF-Token header because they don’t know the CSRF token - Pre-flight requests
A correctly configured endpoint that modifies an app state (e.g. POST, DELETE) requires OPTIONS as pre-flight request that makes the browser block the POST request because it discovers the origin is different.
Implementation details: as you are minting JWT by yourself, you must bring a cryptographic library, and don’t forget to add an actual cypher! (see no encoding).
And you ought to setup Auth.js correctly: its handler should be in /api/auth/[...nextauth]/route.ts, authOptions should include session, providers and callbacks, and you must include NEXTAUTH_URL and NEXTAUTH_SECRET to your .env.
Else there would be a “session is null” exception. If something wouldn’t work, debugging at trpc.ts is a good first step.
Testing the authentication
Testing that with curl requires some patience. There’s a three step handshake first. You first get your csrf token to prove from where you’re requesting and write it into cookies. Then, you send your credentials, sending CSRF token twice (as header and in cookies), and receive your JWT token, putting that in cookies. Finally, you attack cookies to your API requests. I know some devs prefer Postman to that, but attaching screenshots from that app felt kinda boring, so I’m attaching curls instead.
# getting the CSRG tokencurl -s -c cookies.txt localhost:3000/api/auth/csrf
# Getting the JWT. copy the token and paste to "csrfToken"curl -s -X POST -c cookies.txt -b cookies.txt \-H "Content-Type: application/x-www-form-urlencoded" \-d "csrfToken={TOKEN_FROM_ABOVE}&login=admin&password={PW}&redirect=false&json=true" \"localhost:3000/api/auth/callback/credentials"
# Checking if I'm authenticatedcurl -b cookies.txt localhost:3000/api/auth/sessionCompared to equally complex Spring’s security filter chains (unfortunately, their syntax had significantly changed between Spring versions), I wouldn’t say auth in this framework is much easier; we’re left to consolate ourselves with the idea that security is never easy. There are very motivated people who try to exploit every vulnerability they find with their software - protecting from that isn’t cheap.
Security-related code:
import type { NextAuthOptions } from "next-auth";import CredentialsProvider from "next-auth/providers/credentials";import { compare } from "bcryptjs";import { eq } from "drizzle-orm";import { db } from "@/db";import { users } from "@/db/schema";import { credentialsSchema } from "@/lib/schema/credentials";
export const authOptions: NextAuthOptions = { session: { strategy: "jwt", maxAge: 30 * 24 * 60 * 60 }, providers: [ CredentialsProvider({ name: "Credentials", credentials: { login: { label: "Login", type: "text" }, password: { label: "Password", type: "password" }, }, async authorize(credentials) { // TODO: rewrite this as well, important const parsed = credentialsSchema.safeParse(credentials); if (!parsed.success) return null;
const rows = await db .select() .from(users) .where(eq(users.login, parsed.data.login)) .limit(1);
const row = rows[0]; if (!row) return null;
const valid = await compare(parsed.data.password, row.password); if (!valid) return null;
return { id: row.id, login: row.login }; }, }), ], callbacks: { jwt({ token, user }) { // TODO: as well, rewrite me if (user && "id" in user && "login" in user) { token.id = user.id as number; token.login = user.login; } return token; }, session({ session, token }) { if (session.user) { return { user: { name: token.name || null, image: token.picture || null, email: token.email || null, }, expires: session.expires } } return session; } },};Part 4 - Presentation layer
Presentation layer - getting started
This part is comparably easy. All you do is a couple of promts to your favorite agentic IDE. After all, it’s just a React/Tailwind without any SPA-style complexity. The really positive change with the SSR approach - as well as the modern server-driven UIs - is that when you get to the presentation layer, most of your work is done. For example, here are client app providers:
"use client";// ...// Scaffoldingexport const Providers = ({ children }: { readonly children: React.ReactNode }) => { const [queryClient] = useState(() => new QueryClient()); const [trpcClient] = useState(() => trpc.createClient({ links: [httpBatchLink({ url: `${getBaseUrl()}/api/trpc` })], }), );
return ( <SessionProvider> <trpc.Provider client={trpcClient} queryClient={queryClient}> <QueryClientProvider client={queryClient}>{children}</QueryClientProvider> </trpc.Provider> </SessionProvider> );};Presentation layer - comments:
- Smart and dumb components separation. E.G. book/page.tsx is smart. It fetches the data and hosts the state (isLoading, isError). AddBookForm is smart too: it sends a book and invalidates getBooks on success. Everything else (BookGallery, BookPage) that is dumb. They receive their properties, draw their elements and maybe display a navigation URL. Not getting into details, it’s enough to know that while Angular has @Input and @Output (and likes immutability there), React has component props and allows you to include callbacks.
// ... // Smart and dumb components pattern return ( <> {isAuthenticated && <AddBookForm /> /* TODO: explain this */} <BookGallery books={bookList} isAuthenticated={isAuthenticated} onDelete={handleDelete} deletePendingId={deletePendingId} /> </> );}- Navigation: The routing is implicit. Instead of using a
router.tsto declare that /books point to BookGalleryComponent that has BookResolver to fetch data, here you place page.tsx under /app/books. This “books” will be your URL. Try to not define URL’s (for redirecting) repeatedly in different components, keep them in some central routing-related file. - Fetching: To fetch data, you don’t wrap a HTTP call with Observable and you don’t call it from Resolver to have your data ready before the component is rendered; instead, you import tRPC and tell it to getBooks.useQuery() - BFF pattern surely simplifies some things!
- Forms: very basic, compared to enterprise monsters I’ve seen with Reactive Forms in Angular:
// Tiny sized form in React: // ... return ( <form onSubmit={handleSubmit(onSubmit)}> <input id="title" {...register("title")} /> {errors.title?.message != null && <p>{errors.title.message}</p>} <input id="year" type="number" {...register("year")} /> {errors.year?.message != null && <p>{errors.year.message}</p>} <input id="isbn" {...register("isbn")} /> {errors.isbn?.message != null && <p>{errors.isbn.message}</p>} <input id="price" type="number" {...register("price")} /> {errors.price?.message != null && <p>{errors.price.message}</p>} <button type="submit" disabled={createBook.isPending}> {createBook.isPending ? "Loading..." : "Add"} </button> </form> );}Form validation:
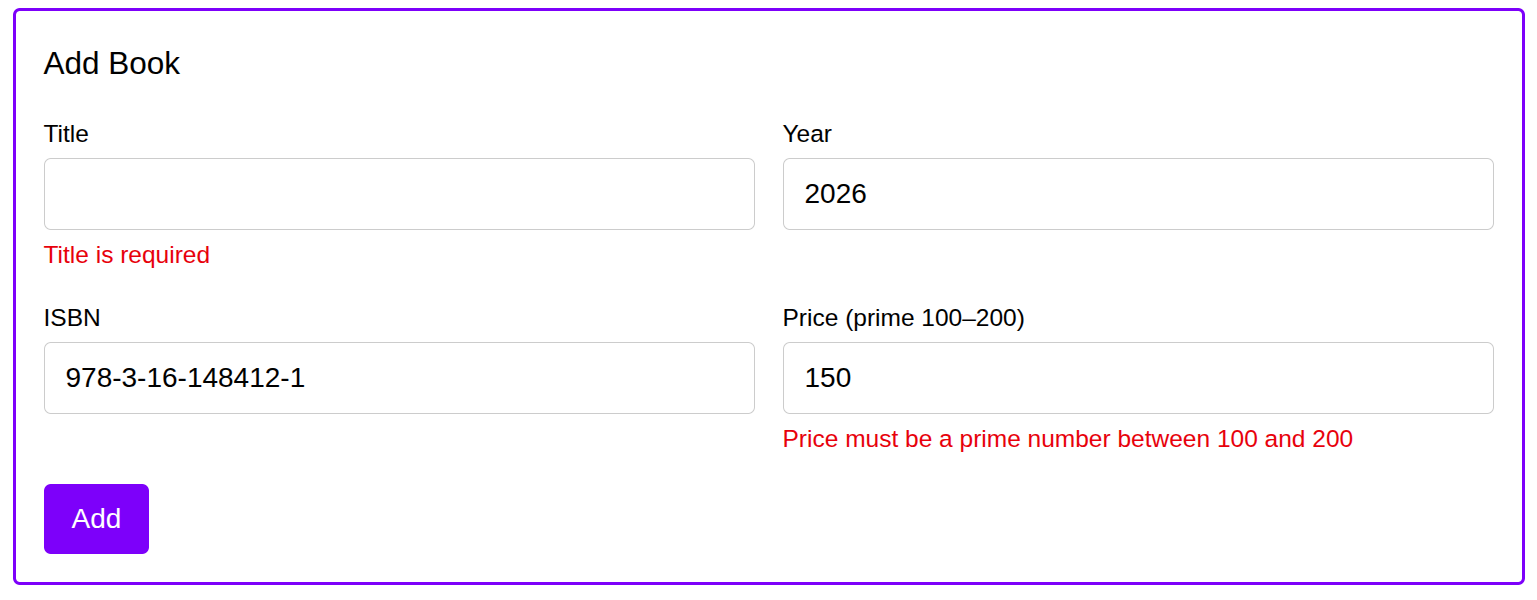
After that, then some CSS, a shared subheader, hiding protected buttons/components for non-authorised users, add redirects (e.g. on login) and you’re done. Simple prompts / simple FE development.
Wrapping up
We have built a more or less complete SEO-friendly CRUD app with authorization/authentication, and a JavaScript setup that hides the more annoying sides of this language. API routing, data validation, ORM+database seed and presentation details are done with reasonable defaults. We have AGENTS.md to help with AI-assisted development as well, and a secure way to seed the database with your admin password.
Ten years ago, building that at the same speed would be positively impossible. So withness how far the progress have reached. As well, this little example demonstrates that most solutions are situational: you ought to understand at least two paradigms of building web apps - SPAs and SSR. (Add static HTML sites - like Javadocs - for yet another paradigm).
As well, with the rise of AI-assisted development (I had little problems building this app by prompting and reviewing, despite being unfamiliar with both React and Next.js) it’s less and less about knowing the precise language syntax and idioms while more and more about understanding the requirements, the tools and the trade-offs.
How many bugs did I introduce, using AI-assisted development on a bookstore built with technologies I’m only starting to learn? Who knows. Needs users to really make the app alive. Also, we didn’t touch CI/CD, or even a manual deploy 6.
As said above, the code together with prompts is available on the GitHub page, see also README.md, AGENTS.md and /prompts folder.
Good luck building apps you would later enjoy!
Appendix
Footnotes
-
A CRUD application is a software program that allows users to Create, Read, Update, and Delete data, typically managing records in a database. ↩
-
There is a book appropriately named “JavaScript: The Good Parts” by Douglas Crockford, but I would personally endorse “JavaScript For The Impatient” by Cay Horstmann, Java champion ↩
-
Another popular ORM, Prisma is talked to in a style that seems different both from SQL and from Java’s CriteriQuery API at first glance ↩
-
Because no one except your server needs to read the token. Enough to show it to the server to be authenticated - the principle of the least required privilege; ↩
-
AWS Cognito also gave us an enterprise level set of features in return. It had a UI library (AWS Amplify) that took care of everything from “Forgot Password” flow to UI login form to OAuth from Google. I have an earlier blog post on that topic: using Amplify UI + AWS Cognito in Angular ↩
-
Github actions into your favourite virtual private server; or add dockerfile and run it from ECS; you’ll need a CDN, a domain and a public RSA key to provide HTTPs; ↩
Comments
No comments yet.